
Mastering JMeter Csv Data Set Config
You're probably asking several legitimate questions:
- How can I simulate concurrent users with unique logins using JMeter ?
- How can I split JMeter CSV Data Set over multiple load generators in case of Remote Testing?
- Is there a solution to Randomize the content of the CSV before a test run?
Let me tell you a secret: you'll get all the answers below.
You will learn how to swarm your system with dynamically behaving users thanks to JMeter CSV Data Set Config.
Ready to make a leap forward in your JMeter skills? Let's get to the business.
How CSV Data Set Config Works¶
When recording a test scenario, most of the time you will have to input some data in the application. This might not be a very important step, like entering your postal address before submitting your order. In there you could put anything remotely close to an address and the application wouldn't care.
The key to properly simulate the behavior you want is to master how the CSV Data Set works.
Add CSV Data Set¶
To add a CSV Data Set to your Test Plan, follow this procedure:
- Right-click on the Test Plan,
- Select Add, then Config Element, then CSV Data Set.
By adding it on Test Plan level, all thread groups share the same Data Set.
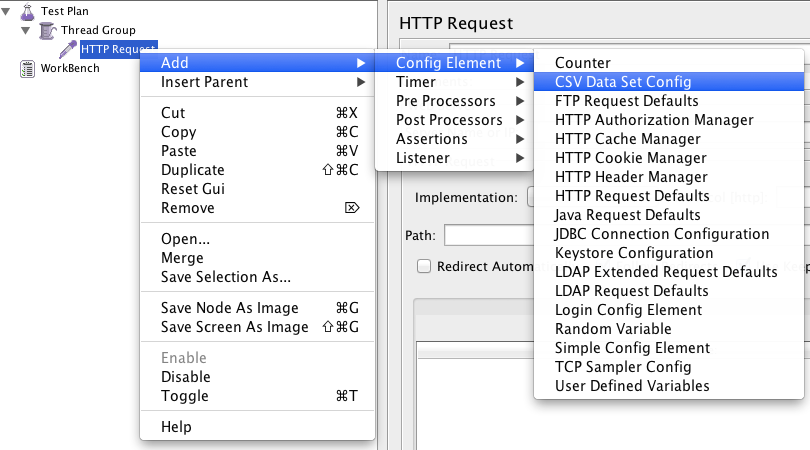
The location where you add the CSV Data Set is important: the variables are set for all elements at same level or below.
Now let's explore how you can configure the Data Set.
Explore Settings¶
Let's take a look at how the CSV Data Set is configured:
- Filename: the path to the CSV file containing the data,
- File Encoding: can be UTF-8 for example. The character encoding affects how the file is read,
- Variable Names: comma-delimited list of names, should be equal number of names than columns in CSV file. Example: login, password.
- Ignore First Line:
falseby default, whenever to ignore the first line as value (because it may contain the column names), - Delimiter:
,by default, can be set to anything else. Suggestion: stick with the default one, - Allow Quoted Data:
falseby default, set totrueif you have double quotes in CSV columns, - Recycle on EOF:
trueby default, should JMeter restart from the beginning when the End Of File is reached, - Stop Thread on EOF: stops the current thread gathering the value if EOF is reached,
- Sharing Mode: defines how values are distributed among concurrent threads.
Wow! There are many settings out there for sure. Let's try different combinations of settings and experience the resulting effect.
Example Settings¶
In JMeter, the way to go is to use a CSV data set config element.
Let's have a look at one together:
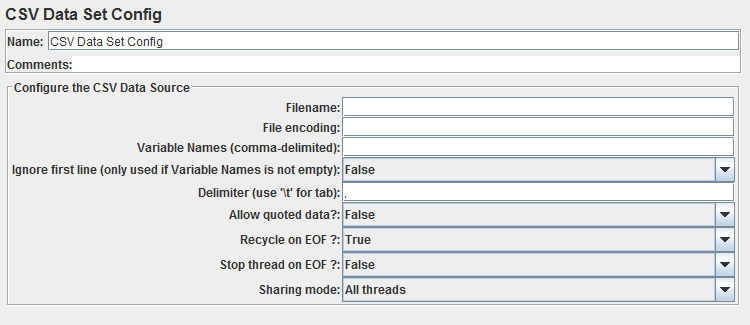
This is its default configuration. To make a basic use of it, we will have to edit a few things. First we are going to use this file:
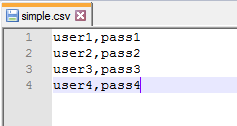
The numbers will help us keep track of which line is used by which thread. Note that the file does not contain any header, so we will enter them in the csv data set config and we will use the default delimiter, a comma. In the end it should look like this:
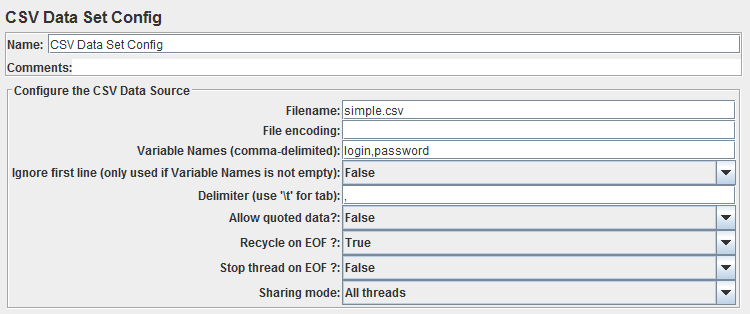
Not that different from the default one, is it?
Just a quick note, for it to work that way, the simple.csv file must be in the same folder than your test plan. Additional details can be found in the official documentation.
Look, now you already master the CSV Dataset configuration. Let's see how it behaves when running a quick test!
Configuring Sharing Mode¶
The crucial part is to get how the Sharing Mode is working. Once you understand it, everything will unfold nicely.
All Threads Sharing Mode¶
As a last addition to our experimental setup, I've written a JSR223 script to log the value of ${login] and ${password}. When we replay with 2 threads + 4 loops each in this configuration what we get is:
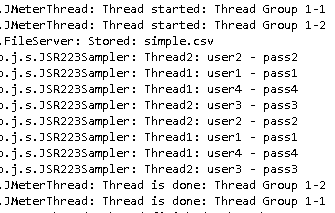
That's actually a good illustration of what the sharing mode means.
None of the two threads is using the same value at the same time because we configured the list to be shared amongst all threads. In this situation, JMeter will give each thread a different value from the file each time they start a new loop.
Another setting we can clearly see is the Recycle on EOF. We had 4 values in this file and ran 2 x 4 = 8 loops total, so after the first 4 loops you can see we went back to the beginning of the list.
This is the point where you are curious about other possible settings.
Current Thread Sharing Mode¶
Now what happens if we change the sharing mode to Current thread ?
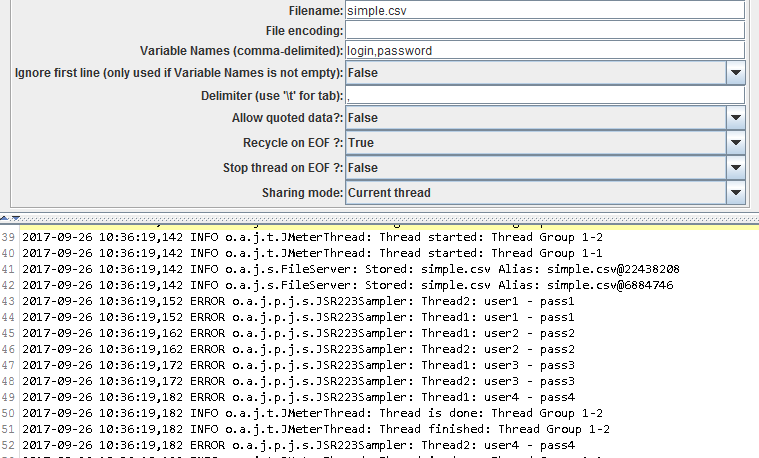
Each thread is now going through its own version of the file, sequentially.
End Of File Behavior¶
Now you're ready to explore the next part: What happens when a thread reaches the end of the file?
Recycle Values On EOF¶
If we deactivate the Recycle on EOF the behavior changes as well:
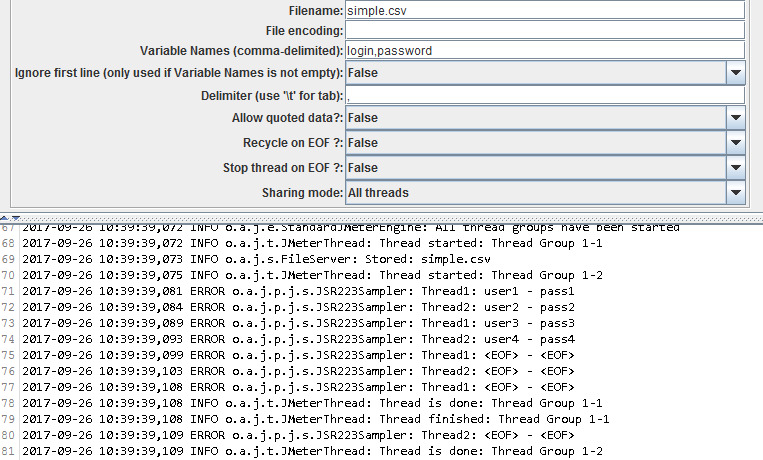
By the way I would not recommend using this option unless you add some control over the value because as you can see it's replaced with \<EOF>.
It may be better to stop the thread instead of getting a weird default value on next iterations.
Stop Thread on EOF¶
Another option is to combine Recycling with Stop thread on EOF this way whenever a thread can't get a new value because the end of the file is reached, the test will automatically stop:
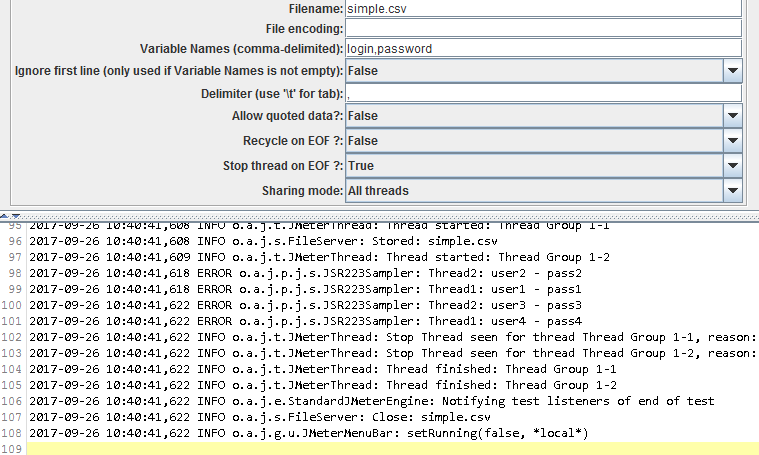
That's particularly useful when dealing with unique data that you can't reuse or need to restore before running another test.
Obviously, some moving parts are still missing. I'm sure you are craving to know answers to the following questions:
- When running a Distributed JMeter Test, how can I split the CSV over the load generators? You obviously want values to be unique,
- Does JMeter Data Set allow to randomize the way values are picked from the CSV file?
As I know you can't wait to get the answer, OctoPerf addresses them all.
OctoPerf Integration¶
The CSV Data set of JMeter is pretty powerful but it lacks some features to make it even easier to run.
Let's see how OctoPerf:
- Centralizes All CSV Files in a single place. Forget about tedious manual CSV File copy before a test run,
- Automatically splits CSV Files when running distributed tests,
- Randomizes the content of CSV Files as requested per the user.
These two powerful features truly make CSV Data Sets fantastically easy to use at scale.
Centralized file menu¶
First we will upload all files to our own file sharing system so that you do not have to worry about if it is on every JMeter instance and where it must be. Just upload the file in our interface, drag & drop is supported. And when configuring your csv, select it from the list:
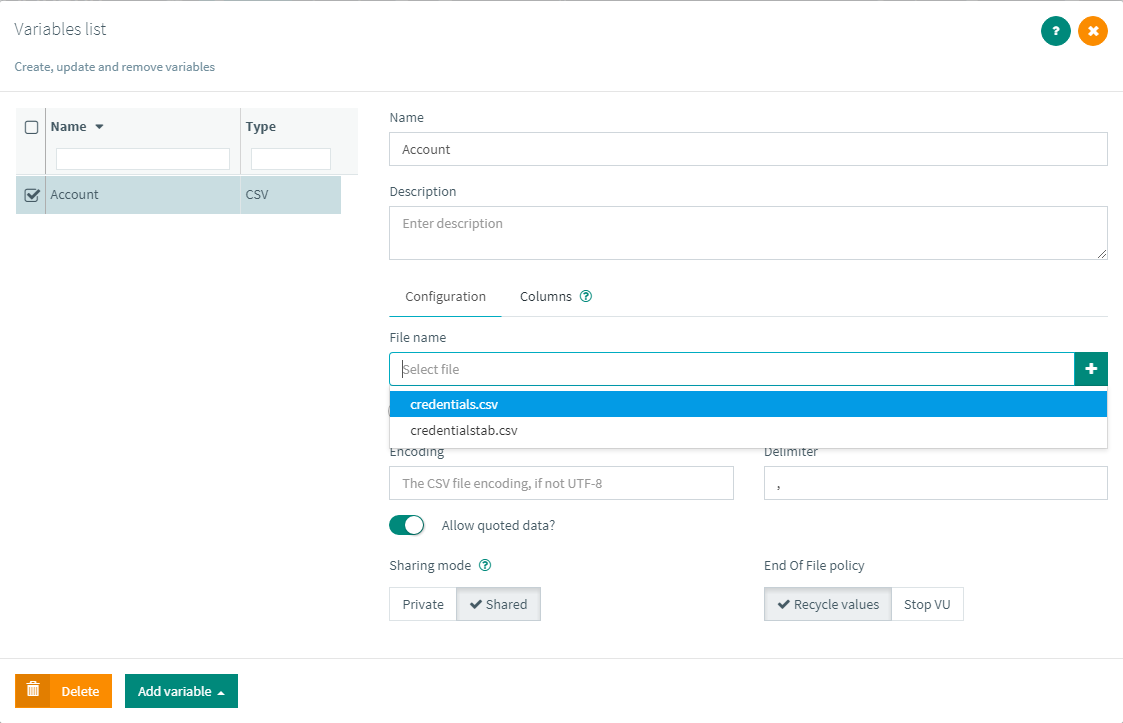
Overview of the file¶
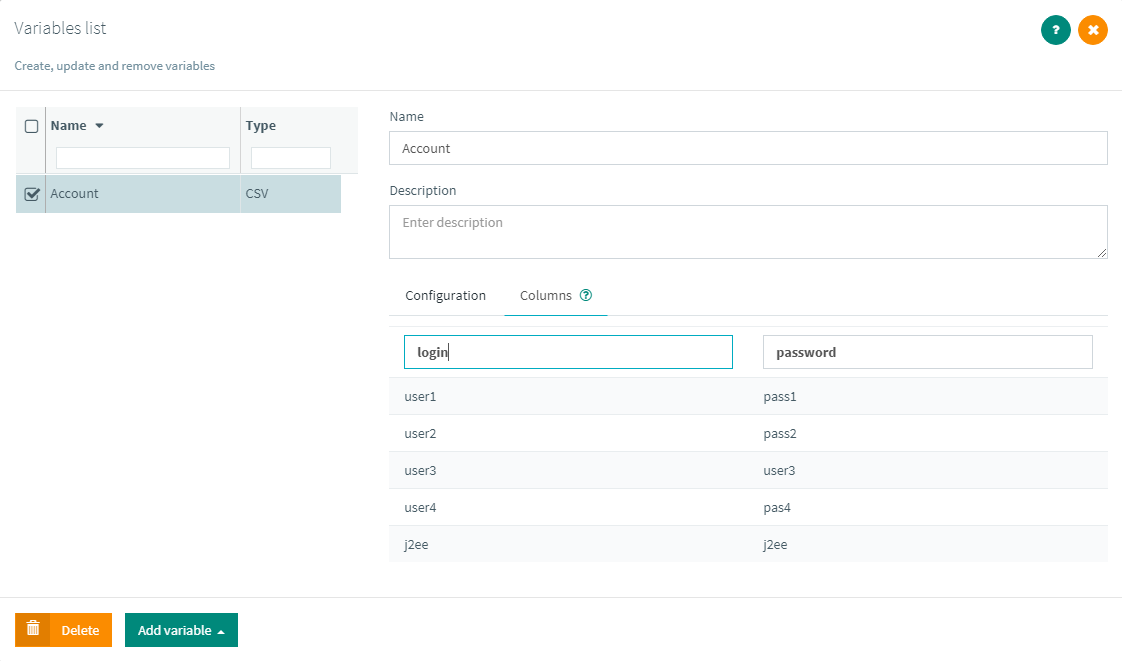
The next tab inside the CSV config screen allows you to see an overview of the file, making it easier and less error prone when naming the columns:
And also, later you can use our auto-completion menu to use your variables. 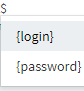
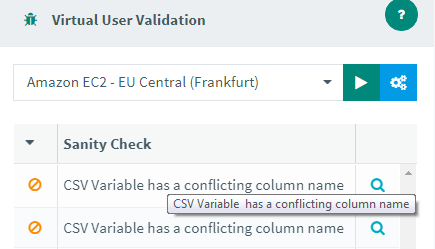
Sanity check for column names¶
One of the problems of CSV Data set in JMeter is that the column name has to be a unique identifier since it's also the variable name. Using the same name for two columns will result in only the first one being used. Which is why we implemented a sanity check control for this specific topic:
Automatic split between load generators¶
When you plan on running a distributed load test and would like the values to be unique per thread, JMeter requires you to split the file manually across all the instances you want to use. This process can be quite long depending on your test configuration. But in OctoPerf we will automatically split the file between all the JMeter instances so that you do not have to worry about it.
Randomization of the file content¶
Another thing you cannot do in JMeter is randomize the order of values in the file.
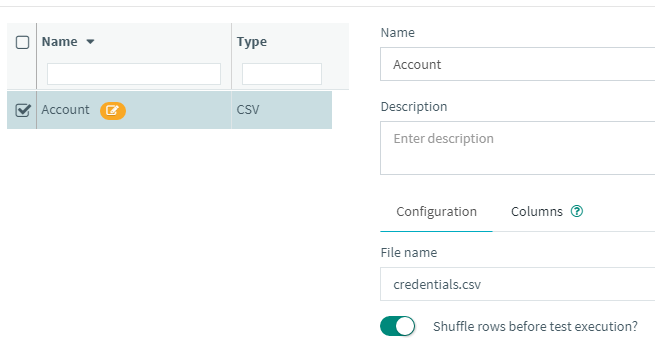
With this option we will shuffle the values before splitting the file across all test machines.