
Spring Boot + Hazelcast Tutorial
It all started when we had the following problem: How can you enable High Availability in a Rest API based on Spring Boot?
As you may know, we have two products: (both based on Spring Boot)
- OctoPerf Saas-Edition: the online saas platform,
- OctoPerf Enterprise-Edition: the full on-premise installable version.
While Saas-Edition absolutely needs High Availability, the Enterprise-Edition doesn't share the same requirements. But, as astonishing as it may seem, both versions share exactly the same code, while working slightly differently.
That's how I've come up with an elegant solution I'd like to share with you. This article aims to give an answer to multiple problems arising when clustering a web application (and especially Rest APIs):
- Get an understanding of why clustering is inherently difficult (but not insurmountable),
- How to hide clustering problematics behind a service that handles the difficult work for us,
- How to enable clustering in a Spring Boot Rest API? Which framework should I use? (obviously we're talking about
Hazelcasthere) - How to make your Spring Boot App configurable to support High Availability without changing a single line of code, (using
@ConditionalOnProperty) - How to implement a very simple Leader Election mechanism using Hazelcast and know when your instance is the leader.
The whole article is based on real-world code examples available on Github. Don't expect any long explanations on Distributed Systems theories.
Architecture¶
Overview¶
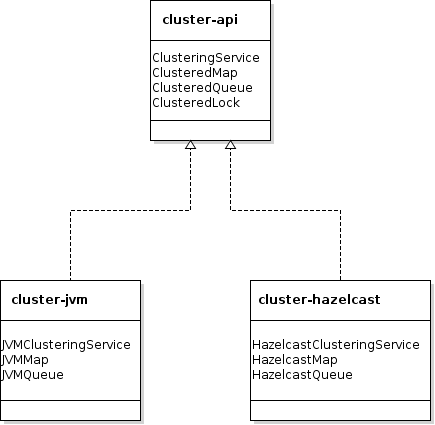
Let's get started by examining the Maven modules which compose this project:
cluster-api: This module defines the API which is going to be implemented, typically as Java Interfaces likeClusteringServiceorClusteredMap<K, V>,cluster-jvm: single node implementation of thecluster-apimodule using Java standard data structures like Map or Queue,cluster-hazelcast: distributed implementation of thecluster-apimodule using Hazelcast.
The architecture is pretty simple: one API and two implementations. Simple and easy to understand. I guess you have a number of questions I'm likely to answer. You may probably ask yourself: Why not use Hazelcast directly?
Why We Encapsulate Hazelcast¶
Because we want to hide the framework providing the distributed data structures to the other parts of the application. There are obviously some drawbacks:
- We need to encapsulate every distributed data structure with our own types like
JVMMaporHazelcastMap, then expose methods likevoid put(K k, V v);through them, - It adds a bit of complexity to the integration because of this indirection.
But, there are also a number of benefits:
- Swappable implementation: should we need to swap Hazelcast for let's say Atomix, the code modification wouldn't impact the code using the
ClusteredServiceat all, - Code Configurability: we'll say in the next coming section that we can control the implementation of
ClusteredServicebeing injected by Spring simply by changing a single property inapplication.yml. That's neat! - Control What's being exposed: while Hazelcast
IMap<K, V>provides numerous methods for many use-cases, it's sometimes overwhelming to have so many possibilities out of the box. I'd rather narrow the choices available by providing a wrapper with less methods.
Let's now examine at class level how the API is architectured.
Separate API from Implementations¶
That's something we have already explained a few years ago in our API Pattern paragraph. Basically, that makes the code configurable without making any change to it.
By simply swapping maven dependencies from one implementing module to another, you can change the application behavior without impacting the code relying on the API.
Class Diagram¶
To make things simpler, I'm just going to expose how JVMClusteringService and JVMMap are implemented. If you take a look at the source available on Github, you will see much more data structures being implemented.
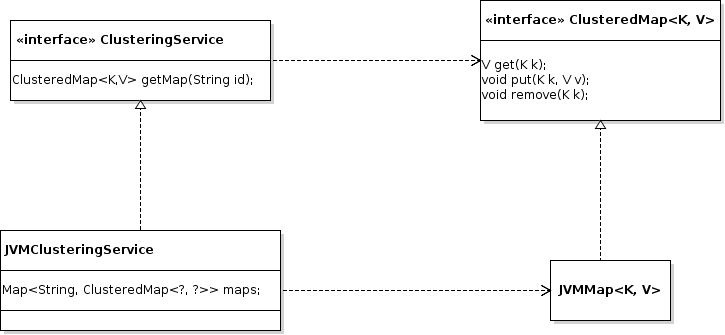
In the schema above, we have the following classes:
ClusteringService: JavaInterfacedefining the service which acts as a factory to provides instances ofClusteredMap<K, V>,JVMClusteringService: Implementation which creates in-memoryJVMMap<K, V>,JVMMap<K,V>: in-memory implementation ofClusteredMap<K, V>based on an in-memoryMap<K, V>.
Interfaces are within the cluster-api module, while JVM implementation is stored within cluster-jvm.
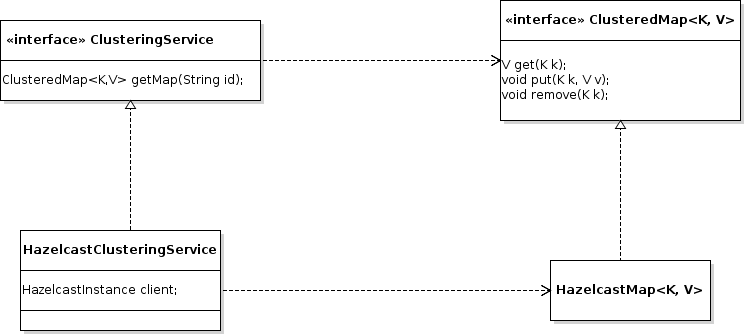
It's not a surprise the Hazelcast module works in a similar manner.We also have the following classes:
HazelcastClusteringService: Implementation which creates distributedIMap<K,V>provided by anHazelcastInstance,HazelcastMap<K,V>:ClusteredMap<K, V>implementation backed by a distributedIMap<K,V>.
Now that we have an overview of the code architecture, we can dive deeper into the content of each module.
Maven Modules¶
As we have seen before, the API is composed of 3 modules: cluster-api, cluster-jvm and cluster-hazelcast.
cluster-api¶
This module only contains the java interfaces. The module is responsible for defining the contract of the clustering API. First, we have the ClusteringService.
package com.octoperf.cluster.api;
public interface ClusteringService {
boolean isLeader();
<K, V> ClusteredMap<K, V> getMap(String id);
}
It exposes the following methods:
boolean isLeader(): returnstruewhen the current instance of the application is the leader, (see Leader Election),<K, V> ClusteredMap<K, V> getMap(String id);: return aClusteredMap<K, V>which encapsulates a single or distributed map.
When a third party code within the application needs a distributed data-structure, the ClusteringService plays the Factory Role: provide those instances without exposing the underlying framework.
ClusteredService cluster;
...
final ClusteredMap<String, String> map = cluster.getMap("id");
map.put("key", "value");
The code using the clustered data-structured must not be aware whenever the application is running as single or multiple nodes in a cluster.
Let's now make a closer inspection of the ClusteredMap<K, V>.
package com.octoperf.cluster.api;
import java.util.Map;
import java.util.Optional;
public interface ClusteredMap<K, V> extends DestroyableObject {
Optional<V> get(final K key);
void put(final K key, final V value);
void remove(final K key);
Map<K, V> copyOf();
}
Along with its companion, the DestroyableObject interface.
@FunctionalInterface
public interface DestroyableObject {
void destroy();
}
There is nothing fancy here: a bunch of standard operations you can perform on a Java Map<K,V>, plus a void destroy() method. The destroy mechanism is designed to destroy the entire distributed data structure when it's not needed anymore.
The thing is: distributed data-structures require explicit destruction. The garbage collector cannot operate on them because of the distributed nature. When a reference to an in-memory map is garbaged, the map is removed from the program memory. Pretty simple.
When a distributed data structure must be garbaged, it must be removed from all the nodes who store a part of it. That's why explicit destruction through void destroy(); method is required.
In the code example on Github you will also find various other data structures like ClusteredAtomicLong or ClusteredQueue. All work similarly to the ClusteredMap. This is why I deliberately don't expose them here.
cluster-jvm¶
This module implements the cluster-api in a single node fashion. ClusteredMap<K, V> is backed by an in-memory map.
package com.octoperf.cluster.jvm;
import ...;
@Service
@FieldDefaults(level=PRIVATE, makeFinal=true)
@ConditionalOnProperty(name = "clustering.driver", havingValue = "noop", matchIfMissing = true)
final class JVMClusteringService implements ClusteringService {
Map<String, ClusteredMap<?, ?>> maps = new ConcurrentHashMap<>();
@Override
public boolean isLeader() {
return true;
}
@Override
@SuppressWarnings("unchecked")
public <K, V> ClusteredMap<K, V> getMap(final String id) {
return (ClusteredMap<K, V>) create(id, maps, JVMMap::new);
}
private <T extends DestroyableObject> T create(
final String id,
final Map<String, T> map,
final Function<DestroyableObject, T> function) {
final DestroyableObject onDestroy = () -> map.remove(id);
return map.computeIfAbsent(id, key -> function.apply(onDestroy));
}
}
Here we already have some interesting code points to discuss:
boolean isLeader()always returnstrue: single node applications are effectively always seen as leader. The reason is that the application is supposed to be running as a single instance,<K, V> ClusteredMap<K, V> getMap(final String id)returnsJVMMap<K,V>instances which forward the calls to an in-memory map,- The service is annotated with
@ConditionalOnProperty(name = "clustering.driver", havingValue = "noop", matchIfMissing = true): This service is instantiated by Spring only when properyclustering.driveris absent or equalsnoop.
Thanks to @ConditionalOnProperty property provided by spring-boot-autoconfigure module, we can design a service whose implementation is instantiated by Spring only in a specific configuration (or in the absence of).
That means JVMClusteredService is activated only when the following configuration:
clustering:
driver: noop
Or, thanks to matchIfMissing = true, when no configuration is specified.
That way our application clustering behavior is configurable. The application can seemlessly run either on a single node, or on multiple nodes using Hazelcast.
package com.octoperf.cluster.jvm;
import ...
@AllArgsConstructor(access = PUBLIC)
@FieldDefaults(level = PRIVATE, makeFinal = true)
public final class JVMMap<K, V> implements ClusteredMap<K, V> {
@NonNull
DestroyableObject onDestroy;
ConcurrentMap<K, V> map = new ConcurrentHashMap<>();
@Override
public Optional<V> get(final K key) {
return ofNullable(map.get(key));
}
@Override
public void put(final K key, final V value) {
map.put(key, value);
}
@Override
public void remove(final K key) {
map.remove(key);
}
@Override
public Map<K, V> copyOf() {
return new HashMap<>(map);
}
@Override
public void destroy() {
onDestroy.destroy();
}
}
The only particularity here is the destroy() method: it delegates to a DestroyableObject provided by the JVMClusteringService which removes the map itself from the ConcurrentMap<?> maps stored in JVMClusteringService.
cluster-hazelcast¶
We're now hitting the interesting part of this tutorial: the Hazelcast implementation.
package com.octoperf.cluster.hazelcast;
import ...
import static lombok.AccessLevel.PACKAGE;
import static lombok.AccessLevel.PRIVATE;
@AllArgsConstructor(access=PACKAGE)
@FieldDefaults(level=PRIVATE, makeFinal=true)
final class HazelcastClusteringService implements ClusteringService {
@NonNull
HazelcastInstance hz;
@NonNull
HZQuorumListener quorum;
@Override
public boolean isLeader() {
final Cluster cluster = hz.getCluster();
final Member leader = Iterables.getFirst(cluster.getMembers(), cluster.getLocalMember());
return leader.localMember() && quorum.isQuorum();
}
@Override
public <K, V> ClusteredMap<K, V> getMap(final String id) {
final IMap<K, V> map = hz.getMap(id);
return new HazelcastMap<>(map);
}
}
First, the boolean isLeader() decides whenever the node is currently the master (or leader as you prefer) by checking the cluster members:
- If we are the first member and the quorum is satisfied, we are the master,
- otherwise, we're a slave node.
I already hear you asking: What is a cluster Quorum?
Suppose you have a cluster of 3 nodes. A network partition happens: 2 nodes can see each other on one side, and one node is isolated alone. The distributed Map<K, V> stored on each node can evolve independently (and diverge) until the 3 machines reconcile. Which version is the right one?
That particular problem is also known as Split Brain. OctoPerf has a few scheduled tasks that must run with the following constraints:
- only a single node must run those batches (they don't support concurrency),
- only the master should execute the batches periodically.
The Quorum enters into action here: it makes sure the minimum number of nodes forming the cluster is present. Should we not have the minimum required nodes, and the node cannot elect itself as master. That way, in case of a split-brain, the single node separated from the 2 others cannot elect it self as master.
Let's inspect the HZQuorumListener.
package com.octoperf.cluster.hazelcast;
import ...
import static lombok.AccessLevel.PRIVATE;
@FieldDefaults(level = PRIVATE, makeFinal = true)
final class HazelcastQuorumListener extends MembershipAdapter implements HZQuorumListener {
int quorum;
AtomicBoolean isQuorum;
HazelcastQuorumListener(final int quorum) {
super();
this.quorum = quorum;
this.isQuorum = new AtomicBoolean(quorum == 1);
}
@Override
public void memberAdded(final MembershipEvent e) {
memberRemoved(e);
}
@Override
public void memberRemoved(final MembershipEvent e) {
isQuorum.set(e.getMembers().size() >= quorum);
}
@Override
public boolean isQuorum() {
return isQuorum.get();
}
}
By constantly watching members come and go, it knows when the quorum is met. No rocket science here!
@AllArgsConstructor(access = PACKAGE)
@FieldDefaults(level = PRIVATE, makeFinal = true)
final class HazelcastMap<K, V> implements ClusteredMap<K, V> {
@NonNull
IMap<K, V> map;
@Override
public Optional<V> get(final K key) {
return ofNullable(map.get(key));
}
@Override
public void put(final K key, final V value) {
map.set(key, value);
}
@Override
public void remove(final K key) {
map.delete(key);
}
@Override
public Map<K, V> copyOf() {
return new HashMap<>(map);
}
@Override
public void destroy() {
map.destroy();
}
}
The HazelcastMap<K, V> implementation is pretty straightforward too. Method Calls are simply forward to the underlying IMap<K, V>.
As Hazelcast requires multiple components (only when clustering.driver: hazelcast), it was worth separating all initialization in a separate Spring @Configuration class.
package com.octoperf.cluster.hazelcast;
import ...
@Slf4j
@Configuration
@ConditionalOnProperty(name = "clustering.driver", havingValue = "hazelcast")
class HazelcastConfig {
private static final Splitter COMA = Splitter.on(',').trimResults();
@Bean
HazelcastQuorumListener membershipListener(@Value("${clustering.hazelcast.quorum:1}") final int quorum) {
return new HazelcastQuorumListener(quorum);
}
@Bean
Config config(
final MembershipListener listener,
@Value("${clustering.hazelcast.members:127.0.0.1}") final String members) throws UnknownHostException {
final Config config = new Config();
final NetworkConfig network = config.getNetworkConfig();
final JoinConfig join = network.getJoin();
final MulticastConfig multicast = join.getMulticastConfig();
multicast.setEnabled(false);
final TcpIpConfig tcpIp = join.getTcpIpConfig();
tcpIp.setEnabled(true);
for(final String member : COMA.splitToList(members)) {
final InetAddress[] addresses = MoreObjects.firstNonNull(
InetAddress.getAllByName(member),
new InetAddress[0]);
for (final InetAddress addr : addresses) {
final String hostAddress = addr.getHostAddress();
tcpIp.addMember(hostAddress);
log.info("[Hazelcast] New Member: " + hostAddress);
}
}
return config.addListenerConfig(new ListenerConfig(listener));
}
@Bean
ClusteringService clusteringService(final HazelcastInstance hz, final HZQuorumListener listener) {
return new HazelcastClusteringService(hz, listener);
}
@Bean
HazelcastHealthIndicator clusterHealthIndicator(
final ClusteringService cluster,
final HZQuorumListener listener,
final HazelcastInstance hz) {
return new HazelcastHealthIndicator(cluster, listener, hz.getCluster());
}
}
The whole configuration is activated only when clustering.driver: hazelcast through annotation: @ConditionalOnProperty(name = "clustering.driver", havingValue = "hazelcast").
Here we have the following beans instantiated:
HazelcastQuorumListener: takes care of computing if the quorum is met,Config: Hazelcast configuration based on TCP/IP discovery through explicit members definition. This allows for DNS Discovery when running the application within systems like Kubernetes,ClusteringService: the service being injected in other services requiring distributed data structures,HazelcastHealthIndicator: enables health check through Spring Boot Endpoints on path/actuator/health. Again, systems like Kubernetes can use the HTTP response on that endpoint to determine whenever the application must be restarted.
package com.octoperf.cluster.hazelcast;
import ...;
@AllArgsConstructor(access= PACKAGE)
@FieldDefaults(level=PRIVATE, makeFinal=true)
final class HazelcastHealthIndicator extends AbstractHealthIndicator {
@NonNull
ClusteringService cluster;
@NonNull
HZQuorumListener quorum;
@NonNull
Cluster hz;
@Override
protected void doHealthCheck(final Health.Builder builder) {
builder.withDetail("isLeader", cluster.isLeader());
builder.withDetail("isQuorum", quorum.isQuorum());
builder.withDetail("members", hz.getMembers().toString());
builder.status(quorum.isQuorum() ? UP : OUT_OF_SERVICE);
}
}
Again nothing fancy here: the application is UP and running only when the quorum is met (leadership is not required). At OctoPerf, we use the health endpoint through Rancher to determine whenever the Docker container running the application must be destroyed and recreated (in case of split-brain).
Let's examine the last module: application. It provides a bootstrap class (to start a simple Spring Boot Web Server) and a RestController.
application¶
The application module ties everything together. Let's take a look at the maven dependencies:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spring-boot-hazelcast</artifactId>
<groupId>com.octoperf</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>application</artifactId>
<dependencies>
<dependency>
<groupId>com.octoperf</groupId>
<artifactId>cluster-jvm</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>com.octoperf</groupId>
<artifactId>cluster-hazelcast</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
As you can see, it depends both on cluster-jvm and cluster-hazelcast. Usually, having multiple implementations of the same interface (like ClusteringService) leads to failure: Spring doesn't know which one to inject in services using it.
But, here we have both services annotated with @ConditionalOnProperty with mutually exclusive conditions. That way, we can control the implementation being injected depending on the application configuration.
Then, we have the bootstrap class to launch the application.
package com.octoperf;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(final String[] args) {
SpringApplication.run(Application.class, args); // NOSONAR
}
}
Ì'm also exposing a sample RestController to interact with the distributed map.
package com.octoperf;
import ...;
@RestController
@RequestMapping("/cluster")
@AllArgsConstructor(access = PACKAGE)
@FieldDefaults(level = PRIVATE, makeFinal = true)
class ClusterController {
private static final String MAP_ID = "map";
@NonNull
ClusteringService clustering;
@GetMapping("/is-leader") boolean isLeader() {
return clustering.isLeader();
}
@GetMapping("/{key}")
Optional<String> get(@PathVariable("key") final String key) {
final ClusteredMap<String, String> map = clustering.getMap(MAP_ID);
return map.get(key);
}
@PutMapping("/{key}/{value}")
void get(@PathVariable("key") final String key, @PathVariable("value") final String value) {
final ClusteredMap<String, String> map = clustering.getMap("map");
map.put(key, value);
}
@DeleteMapping("/{key}")
void delete(@PathVariable("key") final String key) {
final ClusteredMap<String, String> map = clustering.getMap("map");
map.remove(key);
}
}
That way, we can try various combinations:
- a single node application using
cluster-jvm, - a multi node application using
cluster-jvm, - and a multi node application using
cluster-hazelcast.
Let's interact with those rest endpoints through command-line using curl.
Example Application¶
The application can be run for your favorite IDE (Eclipse or Intellij) by running the Application class directly. By default, the application runs in single node mode (using cluster-jvm implementation).
To enable Hazelcast, you must run the application by specifying -Dspring.profiles.active=hazelcast. The application is provided with a application-hazelcast.yml which activates only when hazelcast profile is enabled and contains:
clustering:
driver: hazelcast
hazelcast:
quorum: 2
Single Node Setup¶
First let's start the application without specifying any profile on startup. The application should start within seconds on a random HTTP port.
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.0.2.RELEASE)
2018-06-11 15:32:09.792 INFO 221189 --- [ main] com.octoperf.Application : Starting Application on desktop with PID 221189 (/home/ubuntu/git/spring-boot-hazelcast/application/target/classes started by ubuntu in /home/ubuntu/git/spring-boot-hazelcast)
2018-06-11 15:32:09.795 INFO 221189 --- [ main] com.octoperf.Application : No active profile set, falling back to default profiles: default
2018-06-11 15:32:09.852 INFO 221189 --- [ main] ConfigServletWebServerApplicationContext : Refreshing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@2667f029: startup date [Mon Jun 11 15:32:09 CEST 2018]; root of context hierarchy
2018-06-11 15:32:11.329 INFO 221189 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 0 (http)
2018-06-11 15:32:11.357 INFO 221189 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2018-06-11 15:32:11.358 INFO 221189 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.5.31
2018-06-11 15:32:11.376 INFO 221189 --- [ost-startStop-1] o.a.catalina.core.AprLifecycleListener : The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: [/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib]
2018-06-11 15:32:11.537 INFO 221189 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2018-06-11 15:32:11.537 INFO 221189 --- [ost-startStop-1] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1689 ms
2018-06-11 15:32:12.279 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.ServletRegistrationBean : Servlet dispatcherServlet mapped to [/]
2018-06-11 15:32:12.283 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'characterEncodingFilter' to: [/*]
2018-06-11 15:32:12.283 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'hiddenHttpMethodFilter' to: [/*]
2018-06-11 15:32:12.283 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'httpPutFormContentFilter' to: [/*]
2018-06-11 15:32:12.283 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'requestContextFilter' to: [/*]
2018-06-11 15:32:12.283 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'httpTraceFilter' to: [/*]
2018-06-11 15:32:12.284 INFO 221189 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'webMvcMetricsFilter' to: [/*]
2018-06-11 15:32:12.414 INFO 221189 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-06-11 15:32:12.610 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@2667f029: startup date [Mon Jun 11 15:32:09 CEST 2018]; root of context hierarchy
2018-06-11 15:32:12.702 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/cluster/is-leader],methods=[GET]}" onto boolean com.octoperf.ClusterController.isLeader()
2018-06-11 15:32:12.704 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/cluster/{key}],methods=[GET]}" onto java.util.Optional<java.lang.String> com.octoperf.ClusterController.get(java.lang.String)
2018-06-11 15:32:12.704 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/cluster/{key}/{value}],methods=[PUT]}" onto void com.octoperf.ClusterController.get(java.lang.String,java.lang.String)
2018-06-11 15:32:12.704 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/cluster/{key}],methods=[DELETE]}" onto void com.octoperf.ClusterController.delete(java.lang.String)
2018-06-11 15:32:12.707 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
2018-06-11 15:32:12.708 INFO 221189 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity<java.util.Map<java.lang.String, java.lang.Object>> org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.error(javax.servlet.http.HttpServletRequest)
2018-06-11 15:32:12.740 INFO 221189 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-06-11 15:32:12.740 INFO 221189 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-06-11 15:32:13.057 INFO 221189 --- [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 2 endpoint(s) beneath base path '/actuator'
2018-06-11 15:32:13.067 INFO 221189 --- [ main] s.b.a.e.w.s.WebMvcEndpointHandlerMapping : Mapped "{[/actuator/health],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>)
2018-06-11 15:32:13.068 INFO 221189 --- [ main] s.b.a.e.w.s.WebMvcEndpointHandlerMapping : Mapped "{[/actuator/info],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>)
2018-06-11 15:32:13.068 INFO 221189 --- [ main] s.b.a.e.w.s.WebMvcEndpointHandlerMapping : Mapped "{[/actuator],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto protected java.util.Map<java.lang.String, java.util.Map<java.lang.String, org.springframework.boot.actuate.endpoint.web.Link>> org.springframework.boot.actuate.endpoint.web.servlet.WebMvcEndpointHandlerMapping.links(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
2018-06-11 15:32:13.131 INFO 221189 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2018-06-11 15:32:13.170 INFO 221189 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 28497 (http) with context path ''
2018-06-11 15:32:13.174 INFO 221189 --- [ main] com.octoperf.Application : Started Application in 3.772 seconds (JVM running for 4.293)
Find the line starting with Tomcat started on port(s):, it shows the port on which the server is running.
To put something into the map, you can call the endpoint using curl (on Ubuntu).
curl -XPUT localhost:28497/cluster/key/value
This puts the value value with key key in the map. Now let's try to retrieve the value being associated:
curl localhost:28497/cluster/key
=> "value"
It should print value. Now, if we start a second server (running on port 19017 this time, random one thought), obviously it doesn't see the value which has been put on the first server.
curl localhost:19017/cluster/key
=> "null"
That's completely expected: JVMClusteringService stores the map in an in-memory Map<K, V>. Let's now leverage Hazelcast to share the map between servers.
Multi Node Setup¶
In order to support multi-nodes sharing the same distributed map, let's enable hazelcast profile now. Let's add -Dspring.profiles.active=hazelcast to VM Options.
This time, I start two times the same application. Hazelcast starts and connects both nodes locally:
2018-06-11 18:50:17.861 INFO 55638 --- [ration.thread-0] c.h.internal.cluster.ClusterService : [127.0.0.1]:5702 [dev] [3.9.4]
Members {size:2, ver:2} [
Member [127.0.0.1]:5701 - 09d1d2f3-1632-467e-997b-d688184f07f6
Member [127.0.0.1]:5702 - 561dd489-0ede-43c7-a44b-779c4351f06e this
]
Then I put the value on the first server:
curl -XPUT localhost:28497/cluster/key/value
And get it from the second server:
curl localhost:19017/cluster/key
=> "value"
As expected, the ClusteredMap<K,V> backed by the Hazelcast IMap<K,V> is shared between my nodes. Also, the hazelcast application comes with quorum: 2 configuration.
When both nodes are connected together, the health indicator tells us the application is UP:
curl localhost:19017/actuator/health
=> {"status": "UP"}
But, when only one node is running:
curl localhost:19017/actuator/health
=> {"status": "OUT_OF_SERVICE"}
As the quorum is set at 2, this means at least two nodes must be connected together to form the cluster. The general rule is:
quorum = ceil((N + 1)/2)
Example: for a 3 node cluster, the quorum is 2. For a 5 nodes cluster, the quorum is 3.
The quorum reflects the smallest majority within the cluster. Keep in mind it's recommended to have an odd number of nodes. To understand that let's see how many nodes you can loose before you do not have the quorum anymore:
- 2 nodes: Nothing
- 3 nodes: you can loose one
- 4 nodes: you can loose one
- 5 nodes: you can loose two
And it goes on ...
As you can see, using an even number of nodes does not make you setup more resilient. If anything it makes it weaker by adding more nodes that may fail.
Final Words¶
We've seen so far how to implement distributed primitives like a Map<K, V> using Hazelcast. There are many other Distributed Systems available out there. Atomix is one of those.
As the ClusteringService hides the framework being used, you can easily swap Hazelcast for another framework by creating the relevant module (Example: cluster-atomix). Another advantage is when your application runs on a single node, you can simply use cluster-jvm with no additional startup or memory overhead (compared to using Hazelcast in that case).
Just as reminder, the whole source is available on github project Spring Boot Hazelcast. Feel free to use it in your own project!